Someone pitched me a “crawl optimization” tool this week. It maps your crawl topology, tiers your sitemaps, and tells Google which pages are important. The write-up was genuinely impressive engineering. It was also solving a problem that, for almost everybody, doesn’t exist.
This myth is one of the stickiest in SEO, and it’s worth pulling apart slowly, because the mental model most people carry around is wrong in a way that quietly wastes months of work. So let me do two things: walk through how crawling actually works, step by step, and then show you the one thing that does move the needle — which isn’t crawling at all.
The cartoon in everyone’s head
Here’s the picture most people have, and it goes something like this:
Every day, a spider arrives at your site. It opens your homepage, reads your sitemap, checks the last-modified dates, and then crawls down through your hierarchy — homepage to pillar page to money page — fetching everything, noticing what changed, and updating your rankings accordingly. So if you structure the site cleanly, link your pillars to your money pages, and hand Google a tidy sitemap, the spider rewards you with more crawling, and more crawling means better rankings.
It’s a tidy story. It’s also mostly fiction.
“Pillar page,” “money page,” “topical hub” — these are useful labels for humans talking to other humans on Reddit and LinkedIn. Google doesn’t know what a money page is and doesn’t care. It treats documents as documents. Once you internalise that, the whole “optimize the crawl” project starts to look like rearranging furniture in a house Google isn’t planning to visit.
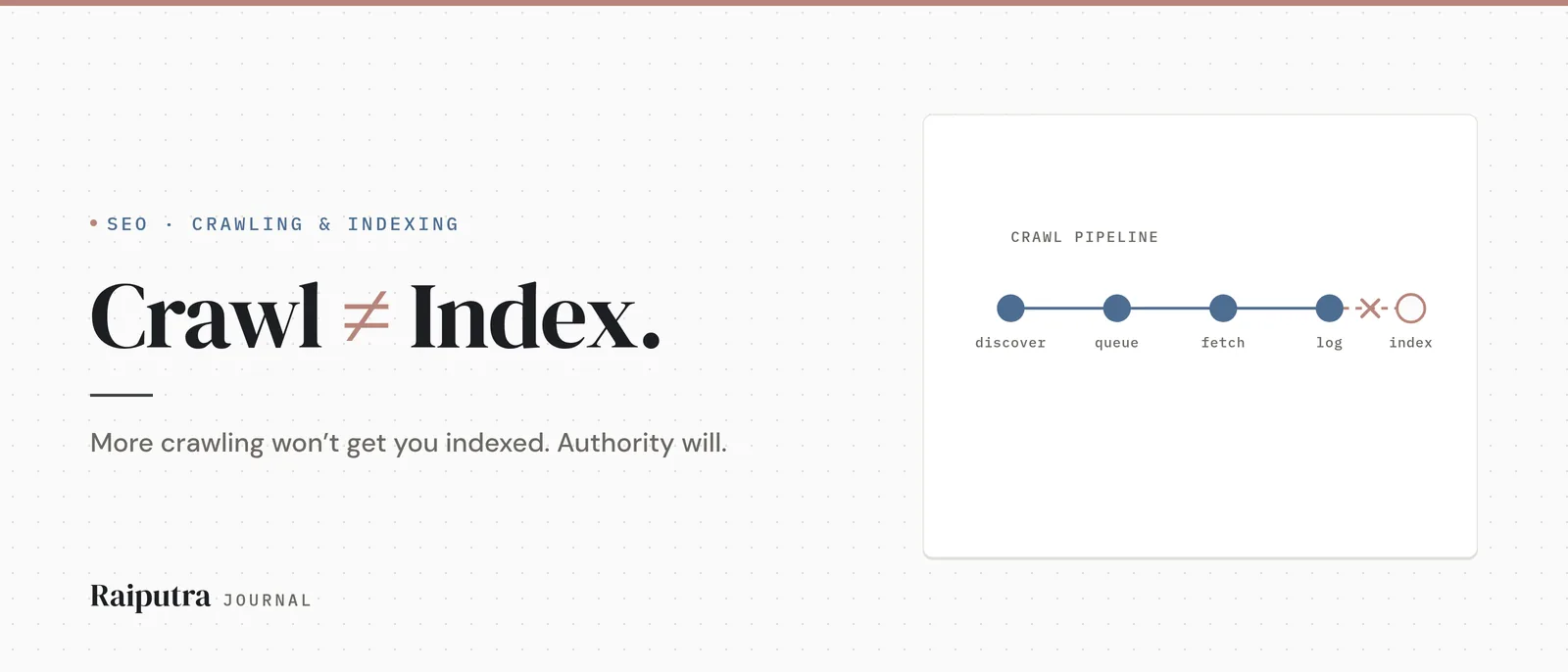
How crawling actually works, step by step
Google itself describes Search as three stages — crawling, indexing, and serving — and is blunt that “not all pages make it through each stage.” Here’s the journey a single URL takes.
Step 1 — A URL gets discovered. Google finds a link on a page it already knows, or your sitemap pings it. That’s discovery. Discovery is not a visit. Nothing has been read yet. A URL can be discovered and then sit untouched for weeks.
Step 2 — The URL waits in a queue. Discovered URLs get scheduled, and they don’t all get equal priority. Google says plainly that “URLs that are more popular on the Internet tend to be crawled more often to keep them fresher in our systems.” A page on a major news site gets fetched in seconds. A page on a brand-new site with no links behind it can sit at the back of the line, discovered but not crawled, for a long time.
Step 3 — Googlebot fetches the page. When the URL’s turn comes, Googlebot requests it. And here’s the part people romanticise: Googlebot is just software. Since 2019 it’s been an “evergreen” crawler running the latest stable Chromium, so it renders modern JavaScript like a current browser would. It’s not a spider with judgment. It requests a URL and gets bytes back.
Step 4 — Failures get logged. If the fetch hits a wall — a 404, a 503, a noindex tag, a redirect loop — Google records the reason. That log is exactly what populates the “why this page isn’t indexed” table in Search Console. So if your page made it to “crawled,” there was no technical difficulty. Stop hunting for one.
Step 5 — A completely separate decision: should this be indexed? Being fetched does not earn a spot in the index. Google is explicit: a page can be “Crawled – currently not indexed” — accessed, read, and still left out, with the note that it “may or may not be indexed in the future.” Indexing, Google says in the same breath as the three stages above, “isn’t guaranteed.”
The takeaway from those five steps is the sentence the tool vendors don’t want framed on your wall: more crawling does not equal more indexing. A low-priority page can be crawled ten times and still never get indexed, because the index decision is waiting on something crawling can’t provide.
The two phrases everyone panics about
Once you’ve got the steps, the two scariest lines in Search Console stop being mysterious:
- “Discovered – currently not indexed” means Google found the URL but hasn’t fetched it yet — often because, in Google’s words, crawling it “was expected to overload the site.” You’re stuck at Step 2.
- “Crawled – currently not indexed” means you cleared Steps 3 and 4 cleanly and got passed over at Step 5.
Neither of those is a sitemap problem. Neither is a “your content format is wrong” problem. One is a queue-priority problem and the other is an index-selection problem — and, as we’ll get to, both of those answer to the same thing.
Crawl budget is a worry for almost nobody
“But what about crawl budget?” Read Google’s own guidance carefully and you’ll see who it’s actually written for: large sites with 1 million+ unique pages changing weekly, or 10,000+ page sites changing daily. If you don’t run something at that scale, crawl budget is not your bottleneck and never was.
Here’s the detail that should settle it: Google removed the crawl rate limiter from Search Console — the last manual dial anyone had — deprecating the tool on 8 January 2024. Googlebot now sets its own pace by watching how your server responds; persistent 500s or slow responses make it automatically back off. That was never a ranking lever to begin with — it was a “please don’t overwhelm my server” valve, and even that is now automatic.
Sitemaps don’t make Google index anything
A sitemap is a discovery aid, not a command. Google’s documentation says it directly: “A sitemap helps search engines discover URLs on your site, but it doesn’t guarantee that all the items in your sitemap will be crawled and indexed.”
The same doc tells you sitemaps earn their keep on large sites, or new sites with few external links. And it says the quiet part out loud about the rest of us: a small site (roughly 500 pages or fewer) that’s comprehensively linked internally may not need one at all. Setting <priority> tags and tiering your sitemaps to tell Google which pages matter doesn’t work, because that’s not how Google decides what matters — it doesn’t take the publisher’s word for it. You can’t declare your own importance. (It’s the same reason you don’t need to invent new machine-readable files to get found, either.)
The thing that actually moves the needle: authority
If priority in the crawl queue and selection into the index both come down to one input, what is it? Authority. Specifically, the links and brand signals that tell Google other people on the web vouch for you.
This is the part the crawl-topology tools tend to skip entirely — and it’s also why “pruning” content or reshuffling your internal link map rarely does much. Authority isn’t a fixed budget that gets thinner the more pages you have. It flows through links, and it decays as it travels. The original PageRank model from Google’s founders used a damping factor of 0.85 — meaning roughly 15% of the value leaks away at every hop. A single great link to your homepage is worth a lot to your homepage. By the time that value has trickled down four or five clicks to a deep product page on a sprawling site, there’s almost nothing left. No topology map fixes that. Only more authority, closer to the page, does.
There’s a deeper reason authority carries this much weight: Google can’t actually grade your prose the way a teacher would. It can’t read a page and know it’s expert or trustworthy. So it leans on signals that approximate those qualities — which is exactly why no tool can hand you an “EEAT score” for content, and why “your page isn’t indexed because the content is too thin” is usually the wrong diagnosis. Give me thin content and enough authority and I’ll get it indexed without touching a word of it.
And this is the same foundation everything downstream sits on. Your visibility in AI search rides on it, because the models read whatever traditional search surfaces — which is precisely why a B2B company can be invisible in ChatGPT for no reason other than weak organic authority.
Don’t let an LLM teach you SEO
A quick warning, because it comes up constantly. People now settle SEO arguments by quoting a chatbot. The problem is that an LLM mostly reflects whatever currently ranks for a query — so if you outrank the page it’s citing, you can literally change its answer. I’ve done it. That makes it a mirror, not an authority.
And no, an LLM built by Google doesn’t secretly understand how Google ranks — owning the model and knowing the ranking system are different things. This is the same “omniscient AI” illusion that trips people up everywhere: the model isn’t reading Google’s mind, it’s reading Google’s results.
The test you can run for the price of a steak dinner
Here’s the experiment that ends most of these debates, and it’s almost free. Buy a $12 domain. Put up a plain, unremarkable page. Then point some real authority at it — a few genuine links from sites that already have standing. Watch it get indexed, content quality untouched.
If a thin page indexes the moment it has authority behind it, then content quality wasn’t the gate. And if a beautifully structured sitemap on an authority-less site doesn’t get its pages indexed, then crawl topology wasn’t the gate either. The variable that changed the outcome is the one to spend your time on.
The bottom line
Crawling is real, and it’s worth understanding — which is exactly why it’s worth not obsessing over. It’s a pipeline: discover, queue, fetch, log, decide. You don’t optimize your way through that pipeline with sitemaps and topology maps. You earn your way to the front of it with authority, and the crawling follows.
Stop tuning the crawl. Go earn the links.
B2B SEO practitioner specialising in search strategy for the AI era. Working directly with marketing managers at mid-size companies — no account managers, no handoffs.